Rất nhiều kỹ sư trên thị trường hiện nay có thể xây dựng một ứng dụng AI (AI App) trong vòng một ngày cuối tuần. Nhưng số lượng người biết cách Vận hành hệ thống AI trên Production (AI Platform Operations) chỉ đếm trên đầu ngón tay.
Sự khác biệt lớn nhất giữa một cái “Demo” và một “Enterprise Platform” nằm ở chữ Observability (Khả năng quan sát/Giám sát).
1. Lỗ Hổng Tử Huyệt (Blind Spots) Của AI Production
Khi ứng dụng web truyền thống gặp lỗi (ví dụ: mất kết nối Database), hệ thống sẽ báo mã lỗi 500. Kỹ sư SRE (Site Reliability Engineer) nhìn vào log là biết cách sửa ngay lập tức.
Nhưng khi AI gặp lỗi, nó sẽ không báo lỗi. LLM sẽ “tự tin” sinh ra một đoạn code chứa bug, hoặc một câu trả lời hoàn toàn sai lệch (Hallucination) với thái độ cực kỳ chuyên nghiệp. Nếu không có hệ thống giám sát, bạn đang chạy xe trên cao tốc với đôi mắt bị bịt kín.
[Production Failure Case Study]: Sự suy thoái thầm lặng (Model Drift) Một hệ thống RAG nội bộ của ngân hàng dùng để hỗ trợ nhân viên tư vấn tín dụng hoạt động hoàn hảo trong 2 tháng đầu. Sang tháng thứ 3, nhà cung cấp LLM Cloud ngầm cập nhật trọng số (weights) của model để tối ưu chi phí. Lập tức, độ chính xác (Accuracy) của hệ thống RAG rớt từ 95% xuống 70%. Nhân viên ngân hàng tư vấn sai lãi suất cho hàng trăm khách hàng. Công ty không hề hay biết cho đến khi khách hàng dọa kiện, bởi vì không có một hệ thống giám sát chất lượng đầu ra (Evals) nào được thiết lập. 📊 Impact Metrics (Hậu quả): Mất uy tín với 400+ khách hàng, đội Pháp chế phải can thiệp đền bù rủi ro lãi suất. 📈 Before/After (Sau khi áp dụng Observability & Evals):
- Before: Thời gian phát hiện lỗi (Mean Time To Detect - MTTD) là 3 tuần (chỉ phát hiện khi khách hàng đã phàn nàn).
- After: MTTD giảm xuống < 5 phút. Pipeline Evals chặn ngay cấu hình model mới nếu điểm chất lượng (Quality Score) rớt dưới 0.90 trên Golden Dataset.
2. Kiến Trúc AI Observability (Tư Duy SRE)
Để tránh thảm họa trên, AI Gateway (LiteLLM) mà chúng ta thiết lập ở Bài 2 phải được kết nối với một hệ thống Telemetry chuyên dụng (như Langfuse, LangSmith, hoặc DataDog LLM Observability).
graph TD
User[Dev / Ops User] --> Gateway[LiteLLM Gateway]
Gateway --> LLM[Cloud / Local LLMs]
Gateway -.->|Async Traces & Spans| Telemetry[Observability Platform<br>*Langfuse / LangSmith*]
Telemetry --> Dash1[Cost & Latency Dashboard]
Telemetry --> Audit[Audit Logs & Prompt Provenance]
subgraph "Evaluation Pipeline (Evals)"
Telemetry -.->|Sampled Outputs| Judge[LLM-as-a-Judge]
Dataset[(Golden Datasets)] --> Judge
Judge --> Drift[Alert: Model Drift / Hallucination]
end
style Telemetry fill:#d4efdf,stroke:#27ae60,stroke-width:2px
style Judge fill:#f9e79f,stroke:#f1c40f,stroke-width:2px
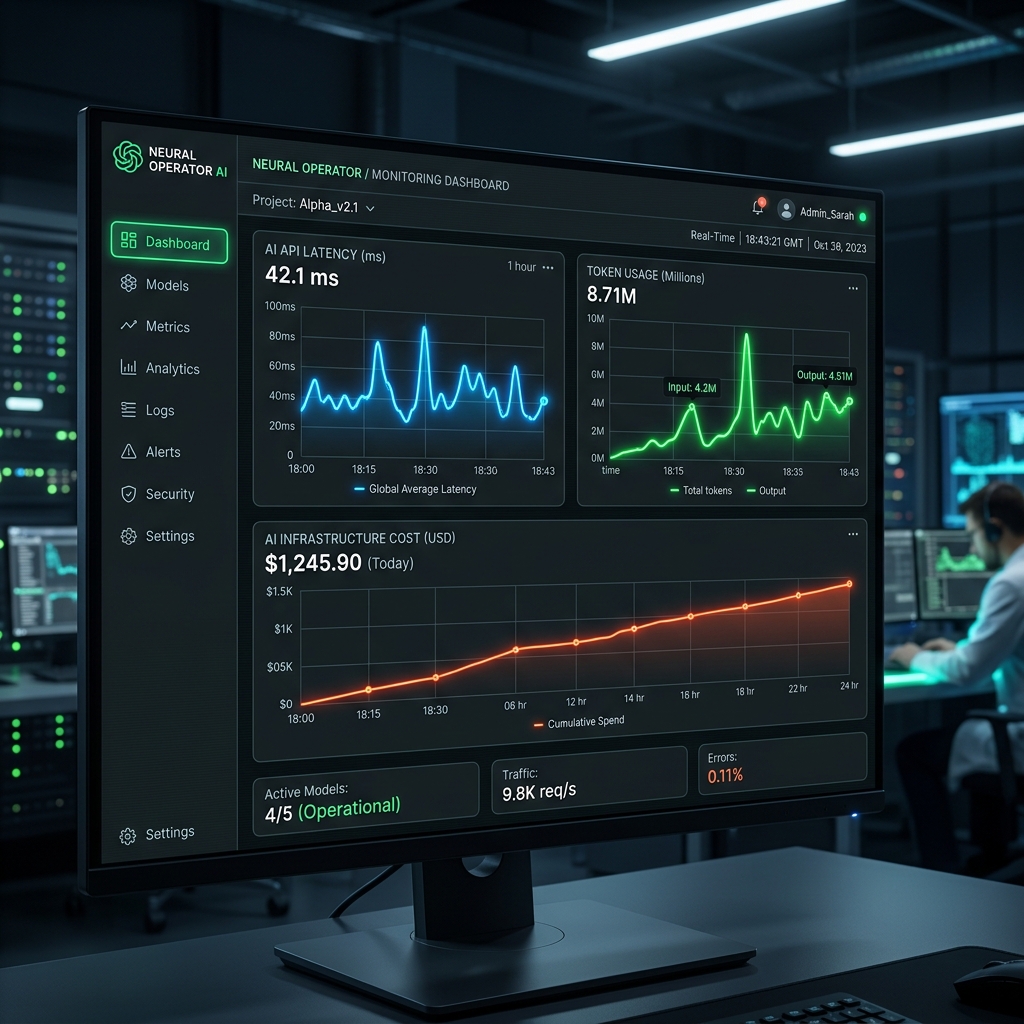
3. Các Chỉ Số Cốt Lõi Cần Giám Sát (Core Metrics)
Đội ngũ Platform Engineering cần theo dõi 4 chỉ số sinh tử sau trên Dashboard:
- Token Cost Monitoring (Giám sát dòng tiền): Biểu đồ chi phí real-time theo từng phòng ban, từng user, từng model. Báo động đỏ (Alert) ngay lập tức nếu team Marketing bất ngờ “đốt” $50/giờ.
- Prompt Tracing (Truy vết ngữ cảnh): Khi AI trả lời sai, SRE phải xem được chính xác chuỗi Prompt đầu vào là gì, RAG đã nhồi những file tài liệu nào vào Context Window.
- AI Latency Monitoring: Theo dõi độ trễ. Nếu model
claude-3.5-sonnetđột ngột mất 15 giây để sinh token đầu tiên (Time-to-First-Token), Gateway phải tự động Fallback Tracking sang model khác và ghi log. - Human Override Flows: Tỷ lệ người dùng bấm nút
Dislike(Thumbs down) hoặc tự tay sửa lại (Override) câu trả lời của AI. Tỷ lệ này cao chứng tỏ hệ thống đang suy thoái.
Bảng mô phỏng Dashboard Giám sát (Ví dụ từ Langfuse/LangSmith):
| Trace ID | User / Team | Model | Tokens | Latency | TTFT (First Token) | Cost | Status / Quality Score |
|---|---|---|---|---|---|---|---|
trc_8x9a | dev-backend | claude-3.5-sonnet | 14,200 | 12.4s | 800ms | $0.04 | ✅ Success (Score: 0.98) |
trc_2b4c | marketing | gpt-4o | 3,100 | 2.1s | 400ms | $0.01 | ⚠️ Overridden (User edited) |
trc_9f1d | sys-agent | local-llama3 | 8,500 | 4.5s | 1200ms | $0.00 | 🛑 Hallucination Detected |
4. Evaluation Pipeline (Evals): Trái Tim Của Việc Scale AI
Trong Kỹ nghệ phần mềm truyền thống: Không deploy code nếu chưa có Unit Test. Trong Kỹ nghệ AI: Không deploy Prompt nếu chưa đi qua Evals Pipeline.
Prompt là Code. Mỗi khi Tech Lead thay đổi một dòng trong .cursorrules (Bài 1), làm sao biết hệ thống sẽ chạy tốt hơn hay tệ đi? Giải pháp là thiết lập Evals (Đánh giá tự động):
4.1. Golden Datasets (Tập Dữ Liệu Vàng)
Bạn cần xây dựng một file chứa khoảng 100 câu hỏi và câu trả lời hoàn hảo nhất (được viết bởi Senior Domain Expert). Đây gọi là Golden Dataset.
4.2. Regression Testing for Prompts
Mỗi khi cấu hình Prompt hoặc cấu trúc VectorDB (RAG) bị thay đổi, luồng CI/CD sẽ tự động lấy 100 câu hỏi trong Golden Dataset đưa cho AI trả lời. Sau đó, dùng một mô hình mạnh (LLM-as-a-Judge) để chấm điểm (Answer Scoring) xem câu trả lời mới có bị lệch so với câu trả lời “Vàng” hay không.
4.3. Retrieval Quality Metrics (Đo Lường RAG)
Đo đạc chỉ số Precision (RAG có lấy đúng tài liệu cần thiết không?) và Recall (RAG có bỏ sót tài liệu quan trọng nào không?). Nếu Precision thấp, có nghĩa là hệ thống đang nạp quá nhiều rác (Noise) vào Context.
💰 Cost Numbers: Chạy Evals pipeline tốn khoảng $10 cho mỗi lần Commit cấu hình mới. Nhưng nó bảo vệ công ty khỏi thảm họa “Model Drift” gây thiệt hại hàng nghìn đô la và làm mất lòng tin của End-user.
Tổng Kết
Chạy AI trên Production là một cuộc chiến dai dẳng. AI Observability cung cấp cho bạn đôi mắt (Dashboards), còn Evals Pipeline cung cấp cho bạn chiếc cân (Metrics) để đo lường chất lượng. Không có 2 thứ này, tổ chức của bạn mãi mãi chỉ đang chạy các bản thử nghiệm (PoC - Proof of Concept).
Tuy nhiên, dù bạn có giám sát hệ thống tốt đến đâu, nếu rào chắn an ninh của bạn lỏng lẻo, Hacker hoàn toàn có thể “Thôi miên” con AI nội bộ của bạn để trích xuất toàn bộ dữ liệu khách hàng.
Đã đến lúc chúng ta phải bọc một lớp áo giáp thép cho toàn bộ nền tảng tại Bài 7 — AI Security Engineering: Phòng Chống Tấn Công Bề Mặt Mới.